首页
产品
图像
语音
解决方案
语音识别
人脸识别
自动驾驶
博客
关于我们
联系我们
产品数据库
通用多模态语音视频数据库
种族:中国人
数量(人) :500
细节:每人录制100个句子。同时使用一部手机录制视频+另外一部手机录制音频+麦克声卡录制音频。三个设备同时录制,并且做了时间同步。人的ID同87-1
查看详细
情绪多模态语音视频数据库
种族:中国人
数量(人) :500
细节:每人录制7类情绪的3个不同句子,每人录制21个不同句子。同时使用一部手机录制视频+另外一部手机录制音频+麦克声卡录制音频。三个设备同时录制,并且做了时间同步。人的ID同87-1
查看详细
通用多模态语音视频数据库
类型 :多模态
数量(人) :500
细节:每人录制100个句子,约6-10分钟
查看详细
情绪多模态语音视频数据库
类型 :多模态
数量(人) :500
细节:每人7类情绪,每个情绪3个不同句子。每人共21个不同句子。
查看详细
中文-普通话-儿童语音数据集
朗读
10060 人
1105.2 小时
查看详细
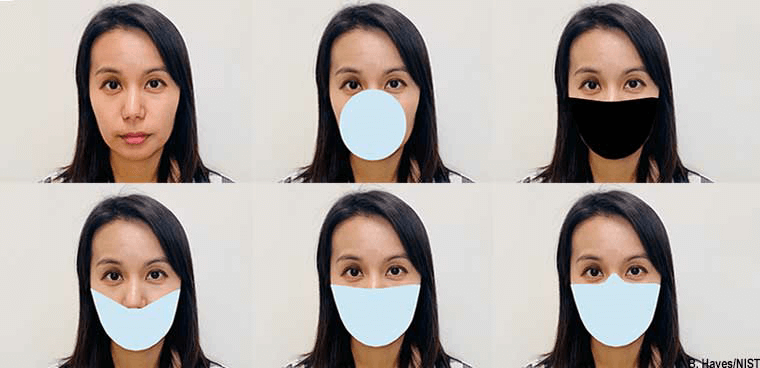
照片攻击数据库
种族:非洲人 2000 中亚人 2000 中国人 2000
数量(人) :6000
细节:1个人10段视频: 2段真人视频,8段照片攻击视频 打印照片,分别漏出眼睛、鼻子、嘴部的区域进行录制攻击视频
查看详细
中文-普通话-直播语音数据集
自然语言
实际直播环境
5079 小时
查看详细
屏幕、布攻击数据库
3,000人
45,000视频
非洲人,中亚人,东亚人
查看详细
英语-美国-客服语音数据集
自然语言
实际客服环境
287 小时
查看详细
面具攻击数据库
1,000人
4,000段视频
不同光照
查看详细
中文普通话和英语-混说语音数据集
朗读
8477 人
4089 小时
查看详细
人脸防欺诈数据库
1,000人
243,600段视频
不同光照
查看详细
英语-北美语音数据集
朗读
1935 人
865 小时
查看详细
多人种3D多表情人脸识别数据库
8400 人
2T
覆盖20多个国家和不同民族
查看详细
中英儿童语音数据集
中英
217 小时
1,000 演讲者
查看详细
非洲人3D多姿态人脸识别数据库
3000 人
1个人1张证件图片+6段视频
左转头,右转头,上抬头,下低头,戴眼镜,头部画圈
查看详细
普通话-中国儿童语音数据集
普通话-中国
1,105 小时
10,060 演讲者
查看详细
南亚印度人3D多姿态人脸识别数据库
2000人
1个人1张证件图片+6段视频
正面,左转头,右转头,上抬头,下低头, 头部转动
查看详细
人体动作识别数据库
种族:中国人
数量(人) :500
细节:使用监控摄像头和RGB-D的摄像头采集摔倒和其它20种常见动作。人的ID同87-1
查看详细
无人车点云数据库
数量(人) :1200000框
细节:数据在中国国内采集,总帧数为7万帧,为视频中截取的秒帧。所标注的3D矩形框为120万个。所标注物体的类别包括了:car、bus、trcuk、van、pedestrian、tricycle、cyclist
查看详细
头部姿态数据库
种族:中国人200 白种人200 黑种人200 南亚人200 其它地区200
数量(人) :1000
细节:每个被采集人使用FaceShift软件建立头模模型(包括10-20个表情的录制),然后录制一段视频 视频分辨率是640X480,视频中被采集人进行左转、右转、抬头、低头、左歪头、右歪头、头部画圈、头部画M形等动作。视频长度4-7分钟。 标注内容:导出的结果中包括了RGB视频和每帧图像中头的pose,包括了yaw、pitch、roll的角度值。
查看详细
旁观者人脸数据库
种族:中国人200 白种人200 黑种人200 南亚人200 其它地区200
数量(人) :1000
细节:1000人分成了180组,每组4-6人 每组在3种光照条件下采集50-69张图片,共采集图像12000张 每组在每种光照条件下拍摄一段视频,共180X3段视频,记录了拍摄照片的全过程 图片分辨率:4000X3000,视频分辨率1080P 标注内容:每张图片中,标注人脸的矩形框,7个关键点,被拍摄人ID,性别,种族。
查看详细
短视频数据库
数量(人) :20000
细节:从抖音上下载的视频数据
查看详细
牛脸数据库
种族:牛
数量(人) :1000
细节:每头牛一段视频,分辨率:1080P,约30 seconds, 30FPS
查看详细
上一页
1
2
3
4
5
6
下一页